Part 2 : D'une architecture monolithique vers une architecture micro-services
Part 2 : D'une architecture monolithiques vers une architecture micro-services
Challenges et bonnes pratiques de mise en œuvre des architectures micro-services
Par Mohamed YOUSSFI .
Dans l'article précédent (https://mohamedyoussfi.blogspot.com/2021/11/blogn-1-dunearchitecture-monolithique.html), nous avons présenté les bases d'une architecture micro-services. La migration d'une architecture monolithique vers une architecture micro-service ne se fait pas sans douleur. il est primordial à l'architecte d'étudier l'impacte des différentes architectures et des challenges de chaque architecture pour effectuer le bon choix selon le contexte du projet. dans cet article, je présenterai quelques éléments clés qu'il faut connaitre pour maitriser le chantier d'une architecture micro-services.


a)
Quel type de
Gateway ?
Le choix du type de Gateway est stratégique pour une architecture Micro-services. Une Gateway est un serveur et conteneur Web. Il est donc important de choisir le bon modèle de gestion des pools de Threads le plus performant. Il existe deux modèles de conteneur web : Modèle Multi-threads avec des entrées sorties bloquante. ZUUL Proxy est un modèle de Gateway qui est basé sur ce modèle. Il est basé sur un conteneur web Tomcat. Au démarrage, Tomcat créer un pool de threads qui seront mobilisés pour traiter les requêtes entrantes en utilisant des entrées sorties bloquantes. A la réception de chaque requête, Tomcat mobilise un thread pour le processus de traitement de la requête qui inclut :
- La lecture des données de la requête
- Effectuer des traitement
- Accéder à la base de données
- Accéder à des services distants
- L’envoie de la réponse
Les étapes 1, 3, 4 et 5 sont des
opérations d’entrées sorties bloquantes qui implique des communications
réseaux. Ce qui signifie que si la latence réseaux est importante (Débit faible),
Le thread sera mobilisé en restant inactif pour une longue durée à cause des
attentes réseaux. Le nombre de threads ne peut pas dépasser un maximum. Par
exemple, dans une configuration par défaut de spring Boot, le maximum size du
pool de threads de Tomcat est 200. Ce qui signifie que Tomcat ne peut pas
traiter plus de 200 requêtes à la fois. Si le temps de traitement des requêtes
est pénalisé par la latence réseaux, on va se retrouver dans une situation ou
tous les threads son mobilisés et par conséquent Tomcat ne peut plus traiter
les requêtes entrantes et les services de l’applications deviennent
indisponibles même si les ressources du serveur (CPU et RAM) son encore
disponibles. L’inconvénient de ce modèle est qu’il n’est pas scalable
verticalement. Cela signifie que même si vous avez un serveur puissant, vous
n’avez pas la garantie que toutes les ressources de votre serveur soient
exploitées à cause des entrées sorties bloquantes qui entrainent la
mobilisation rapide de tous les threads du pool. Un client Web qui dispose donc
d’une connexion très faible impactera négativement les performances votre
serveur. On ne peut pas donc prédire le nombre de requêtes que le serveur peut
traiter par unité de temps. Vous à la merci des du débit des connexions réseaux
des clients web, des bases de données et des services distants. C’est l’un
des inconvénients majeurs des Gateways comme de ZUUL Proxy qui basé sur Spring
MVC Classique. Il utilise le package « java.io » pour gérer les
entrées sorties qui sont bloquantes (InputStream, OutputStream, Reader, Writer,
etc.). Ce modèle marche très bien dans de nombreux cas ou le nombre de requêtes
concurrentes n’est pas important et les latences réseaux sont au bon
rendez-vous. Autrement, il existe un autre modèle qui est beaucoup plus
performant à savoir le modèle Single Thread avec des entrées sorties non
bloquantes.

a)
Modèle Single Thread
avec des entrées sortie non bloquantes
Un autre modèle de Gateway qui
peut être utilisé est Spring Cloud Gateway. Il se base sur un autre modèle qui
permet de se comporter d’une façon différente avec un nombre de threads très
réduits. C’est modèle Single Threads avec de entrées sorties non bloquantes. Ce
modèle est basé sur le package « java.nio » qui a été introduit à
partir de JAVA 7, qui offre aux applications java de gérer les entrées sorties
d’une manière non bloquantes utilisant les « Selectors, Channels et
Buffers). Avec ce package, il est possible de créer un serveur java utilisant
un single Threads pour traiter toutes les requêtes concurrentes de plusieurs
clients en utilisant dans un « Event Loop » les entrées sorties non
bloquantes et un modèle de programmation asynchrone orientée événements. Le
premier conteneur Web qui a implémenté uen variante très efficace de ce modèle
est « Netty ». Ce modèle a été introduit la première fois par la
technologie NodeJS. NodeJS utilise du Java script coté serveur avec la limite
d’un seul thread pour chaque application. Ce qui a contraint les développeur
NodeJS de chercher la solution autour des concepts « Event Loop »,
« Entrées Sorties Bloquantes », « Programmation Asynchrone orientées
événements ». D’autres langages comme Java ont suivi la même technique en
créant le package « java.nio » à partir de la version 7 de Java. Par
la suite des technologies comme Vert.X, qui reprend le même modèle de NodeJS
dans Java a été créé. Par la suite Spring a créé une nouvelle version de son
Framework basée sur ce modèle nommé « Reactive Spring » ou
« Spring Web Flux ». Spring Web Flux est basé sur le conteneur
Web réactif Netty qui fonctionne de la manière suivante :

o
Au démarrage Netty créer un
certain nombre de Threads Limités en fonction du nombre de cœurs du CPU pour
garantir l’exploitations de toutes les unités de calcul du CPU. Un Thread est
utilisé comme Input Output Selector Thread et les autres comme Worker Threads.
o
Le IO Selector Thread est
utilisé dans un « Event Loop » pour d’accepter toutes les connexions et
la requête entrantes en utilisant des entrées sorties non bloquantes et en
empilant et dépilant des événements dans un file d’attente. Ce thread garanti
que toutes les requêtes entrantes seront acceptées tant que les ressources du
serveur (RAM et CPU) sont disponibles
o
Pour compléter le
traitement des requêtes, Netty utilise les Worker Threads pour garantir
l’exploitation de toutes les unités de calcul du CPU.
Ce modèle assure la scalabilité verticale. Ce qui signifie
que :
o On a la garantie que toutes les ressources du serveur vont être
exploitée grâce aux entrées sorties non bloquantes.
o On a la certitude que, tant que les ressources du serveur sont
disponibles, les requêtes entrantes seront acceptées. Ce qui augmente les
performances du serveur.
o Lees performance du serveur ne sera jamais impacté par les
performances de latence réseaux car les entrées sorties sont non bloquantes.
o Avec ce modèle on peut prédire combien de requêtes que le
serveur peut traiter par unité de temps car la latence réseaux n’impacte pas
les performances du serveur.
Pour la Gateway, Il est donc
recommandé de privilégier Spring Cloud Gateway que ZUUL Proxy dans le cas où nous
avons à faire le choix.
A.
Quel Modèle de
communication entre les micro-services ?
Il existe deux façons pour faire
communiquer les micro-services à savoir une communication synchrone ou asynchrone.
a) a) Modèle de communication synchrone :
Pour faire communiquer les
micro-services d’une manière synchrone, on peut utiliser REST qui est le cas le
plus courant. Pour ce faire Spring offre des outils comme RestTemplate pour le
cas du modèle Spring impératif et WebClient pour le cas de Spring Réactif. Au
lieu d’utiliser ces deux modèles d’une manière programmatique pour interagir
entre les micro-services avec REST, il est aussi possible de le faire de
manière déclarative en utilisant OpenFeign. Avec OpenFeign, il suffit de
déclarer une interface qui contient la signature des méthodes à invoquer en les
mappant vers des requêtes http en utilisant les annotations classiques d’un
contrôleur Spring (@GetMapping, @PostMpping, @PathVariable, etc.)

On peut dire que OpenFeign apporte à voter application pour
l’accès aux API REST ce que Spring Data apporte pour l’accès aux données de
votre application.

Il faut juste noter que dans le
cas d’un modèle de Spring impératif avec des entrées sorties bloquantes, pendant
la durée de communication REST en deux micro-services, le Thread reste inactif.
Ce qui fait que la latence à un impact négatif sur les micro-services
communiquant. Ce n’est pas le cas de Spring Reactive (Spring Web FLUX) qui ne
mobilise pas les Threads pour toute la durée de communication des micro-services.
Ce qui ajoute plus de performances à l’application.
a) b) Modèle de communication asynchrone :
La communication synchrone
s’impose dans de nombreux cas, mais si elle est utilisée partout dans l’application,
cela impacte négativement les performances de l’application de temps plus qu’il
est difficile de contrôler les flux de toutes communications http. Il existe un
autre modèle de communication qui est règle le problème de synchronisation
entre les micro-services d’une manière plus efficace à savoir la communication
asynchrone e utilisant un modèle de programmation piloté par les événements
(Event Driven Architecture). Ce modèle nécessite la mise en place d’un Bus
d’événements à travers des Brokers transactionnels comme KAFKA, RabbitMQ ou
ActiveMQ. L’API JMS a été l’initiateur de ce modèle de programmation, mais elle
a été rattrapée et dépassée en termes de performances avec les solutions et
protocoles implémentés par RabbitMQ comme AMQP, MQTT, STOMP et ensuite par
KAFKA qui apporte un modèle monstrueux en dépassant les limites de RabbitMQ.
Cette bataille entre les modèles de Brokers mérite un bel article à part. Pour
découpler le code de l’application du type de Broker à utiliser, Spring fournit
des API génériques comme Spring Cloud Stream et Spring Cloud Stream Function
pour faire profiter votre application de ce modèle de communication piloté par
événements indépendamment du Broker que vous utilisez.
Un exemple qui illustre la
différence entre la communication synchrone et ce modèle asynchrone piloté par
les événements c’est comme si, au besoin,vous appelez, des personnes pour leurs
demander de vous vous fournir des informations impératives pour continuer votre
activité. C’est bien ce qui va se passer si vous utilisez le modèle de
communication synchrone avec OpenFeign. L’inconvénient c’est que vous serez
contraint d’appeler une même personne plusieurs fois pour lui poser la même
question et pour récupérer la même information. Si vous voulez travailler d’une
manière asynchrone, vous dites à vos collaborateurs, si des nouvelles arrivez
chez vous envoyer moi un message SMS ou WhatsApp. Ce qui fait que dans votre
activité, au besoin d’une information qui provient de quelqu’un d’autre, vous
n’avez pas besoin de l’appeler car vous avez tous les événements de vos
collaborateurs chez vous dans vos messages WhatsApp. Il suffit que vous mettiez
en place un Handler d’événement qui structure le contenu de ces événements dans
une base de données de voter coté pour que toutes les données dont vous avez
besoins soient disponibles chez vous. Ceci va réduire le temps de traitement au
niveau des micro-services et éviter d’interagir avec d’autres micro-services
d’une manière synchrone.


Pour mettre en œuvre
unarchitecture idéale de modèle de communication, des Patterns d’architecture
très utiles et recommandés pour ce genre d’architecture sont :
a) - CQRS (Command, Query, Responsability, Segregation) :
un pattern d’architecture qui consiste à séparer le flux de lecture et le flux
d’écriture dans dans une application. Autrement dit, définir dans une
application une base pour l’écriture et une base pour la lecture. Ce pattern
stratégique part du constat que 90% de la charge d’une application représente
des opérations de lecture alors qu’uniquement 10% de la charge concerne les
opérations de modification de données. La scalabilité des services de lecture
et d’écriture ne doit pas être traitée avec les mêmes soins. On aura sans doute
besoin de plus d’instances pour les services de lecture que d’écriture. Un
autre argument important est que les opérations d’écriture ont souvent besoin
d’évoluer dans des transactions et ont besoin d’être sécurisée de manière très
restrictive ce qui n’est pas nécessaire pour les opérations de lecture.
b) - Event Sourcing : Un Pattern architecture qui consiste à à Capturer tous les changements de l’état d’une application Comme Séquence d’Evénements. L’idée est de ne pas se concentrer sur l’état courant de l’application, mais plutôt sur la séquence de changements d’états (Evénements métiers) qui ont abouti à l’état courant. À partir de cette séquence d’événements, on pourra agréger l’état courant de l’application. Tout changement de l’état de l’application a une cause unique (Evénement), (Il n’y a pas de fumée sans feu). Un exemple courant de Event-Sourcing c’est le cas d’un compte bancaire qui a un solde. Au lieu de garder dans la base de données uniquement le solde actuel du compte, on enregistre toutes les opérations effectuées sur ce compte (Débit et Crédit) qui permette de déterminer le solde du compte à une date donnée. Ce pattern apporte à une application beaucoup d’avantage à une application comme
- Construire une Base de d’Audit
- Retrouver facilement l’origine des Bug en Prod
- Reprise de données : En cas de panne, Rejouer tous les événements métiers enregistrées pour retrouver l’état de l’application
- Performances : Modèle asynchrone avec des Bus d’événement qui se mette bien à l’échelle (Scalabilité)
A.
Comment faire pour
le stockage des données ?
L’un des premiers problèmes sur
lesquels il faut trancher dans une architecture micro-service, c’est de décider
si vous allez utiliser une base de données indépendante pour chaque
micro-service. Ce qui représente la solution naturelle préconisée par les architectures
micros-services ou encore utiliser une base de données unique pour tous les
micro-services, ce qui constitut une anormalisation de l’architecture
micro-service. Si vous présentez une
architecture qui utiliser des bases de données distribuées pour les
micro-services, sans doute votre client ne sera pas content. Il vous dira
surement, je veux que toutes les données soient centralisées, stockées et
sécurisée dans une seule base de données. Plusieurs architectes cèdent
rapidement à ce niveau-là pour basculer vers une base de données unique. Ce qui
représente, à mon sens, une mauvaise stratégie qui freinera sans doute le
potentiel énorme des micro-services.

En réalité, il existe des
solutions bien meilleures pour ce problème en utilisant les patterns CQRS et
Event Sourcing. C’est-à-dire, chaque micro-service utilise sa propre base de
données avec un bus d’événement qui permet de construire d’autres bases de
lecture structurée et appropriée à l’utilisation. Vous pouvez donc rassurer
votre client et l’équipe Data pour leur dire que toutes les données de
l’application sont conservées aussi dans une base globale séparée et
synchronisée avec ce qui se passe au niveau de l’application.

B. Security Challenge
des architectures micro-services ?
Dans la pratique, il existe deux modèle deux modèles d’authentification :
- Authentification State full :
Les données de la session de
l’utilisateur authentifié sont stockées dans le contexte du serveur
d’authentification et le client reçoit uniquement le SessionID qui est souvent
stocké dans les cookies coté Brower Web. Par la suite, chaque requête du client
contient le SessionID. Ce qui permet au serveur de consulter dans son contexte
si la session est toujours ouverte. Si c’est le cas, il charge les données de
la session (username, et rôles) dans le contexte de sécurité du serveur. Par la
suite l’application peut décider si l’utilisateur a le droit d’accéder à la
ressource demandée par dans la requête.
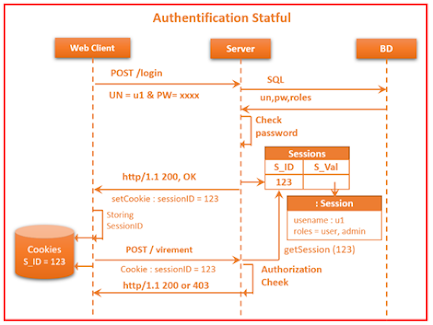
Ce modèle d’authentification est plus pratique pour les applications monolithiques la session de l’utilisateur et toutes les ressources et les fonctionnalités sont déployées dans le même contexte de l’application coté serveur. En revanche, ce n’est pas le cas pour les applications distribuées basées sur les micro-services qui doivent utiliser sans doute un autre modèle d’authentification dit State less.
- Authentification Stateless :
Dans ce modèle
d’authentification, les données de la session de l’utilisateur authentifié est
sont enregistré dans un Token délivré au client. Ce Token doit être présenté
par le client dans toutes ses requêtes à chaque micro-service. Ce dernier peut
restituer la session de l’utilisateur à partir de ce Token. Le serveur
d’authentification n’a pas donc à enregistre dans son contexte les sessions des
utilisateurs authentifiés, mais plutôt délivrer au client sa session dans un
Token qui sera géré par le client lui-même. Parmi les Tokens qui sont utilisés
on trouve JWT (Json Web Token) qui est un token qui stockent les données de la
session au format JSON encodé e Base64URL. Le JWT est un Token Compact,
autonome et signé numériquement. Ce qui permet aux micro-services de faire
confiance à un JWT.

Pour utiliser
des standards plus appropriés à une architecture micro-service, les protocoles
OAuth2 et OpenIDConnect sont souvent utilisé. OpenIdConnect a introduit la
notion de deux tokens JWT : Access Token et Refresh Token pour palier au
problème de révocation de tokens qui est présent dans les JWT. Le JWT Access
Token a une durée d’expiration très courte qui peut être de l’ordre de 5min par
exemple. Cela signifie qu’une fois l’utilisateur authentifié, Le client reçoit
un Token valable uniquement 5 min. Une fois ce timeout expire le client doit
s’authentifier à nouveau pour renouveler son Token. Pour éviter d’obliger l’utilisateur à saisir à
nouveau son usename et son mot de passe, ce qui n’est pas pratique, il suffit à
l’utilisateur de présenter au serveur d’authentification un autre token qui est
le JWT RefreshToken. Ce dernier ayant une durée d’expiration longue (30 jours
par exemple) et signé numériquement est suffisant pour que le serveur fasse
confiance à ce token et par la suite délivrer au client un nouvel Access Token
à l’utilisateur après quelques vérifications du mécanisme de révocation de
Token comme la vérification si le Token n’est pas Black listé ou encore
consulter les droits d’accès de l’utilisateur n’ont pas changés entre temps.
Spring Security permet de mettre facilement des services d’authentification et
d’autorisation respectant Oauth2. Cette partie mérite un article séparé.


Bonjour M. Youssfi, j'apprécie vraiment cette méthodologie. Merci pour toujours que Dieu vous bénisse.
RépondreSupprimerMerci bcp Professeur
RépondreSupprimerMa dose du matin.
RépondreSupprimerQuel régal
thanks to all, Que Dieu vous benisse
RépondreSupprimerParfait comme d'habitude, dans l'attente de votre article qui décrit la bataille entre les modèles de Brokers(que je connais ces grands lignes )
RépondreSupprimerInfiniment merci cher Professeur
RépondreSupprimer